Применение машинного обучения в атрибуции без розовых очков. Опыт OWOX
Если стандартные модели атрибуции для вас уже пройденный этап, и теперь пришло время примерить гибкую модель, которую легко можно подогнать под свой тип бизнеса, — не спешите с выбором. Среди продвинутых моделей атрибуции сейчас лидируют модели на базе технологии машинного обучения (machine learning — ML), которые помогают рассчитать ценность каналов продвижения, основываясь на огромном объеме данных, обработанных алгоритмом.
ML — это лишь инструмент, отдельная технология, и она не решает задачи атрибуции сама по себе, но может быть успешно использована на данных вашего бизнеса.
Для тех, кто подозревает, что не все так радужно с настройкой этих моделей, Владислав Флакс, СЕО OWOX, подготовил детальный разбор ошибок внедрения ML в атрибуции. А те, кто уже твердо решил внедрять эти технологии у себя, могут пройтись по статье как по чек-листу.

Область применения машинного обучения в атрибуции
В зависимости от типа компании функции и задачи маркетингового отдела распределяется по таким уровням:
- СЕО или топ-менеджемент — в зависимости от структуры компании — занимаются стратегическим планированием, отталкиваясь от целей компании, доступного бюджета на офлайн и онлайн, данных рынка. Обычно такая постановка глобальных целей происходит раз в квартал.
- Директор по маркетингу или e-commerce-директор принимают решения о распределении выделенного бюджета по каналам и постановке KPI для контроля расходов и расчета ожидаемых прибылей. Отчеты по этим задачам строятся каждый месяц.
- Менеджеры направлений распределяют выделенный бюджет по кампаниям и приводят свои KPI к общему знаменателю с верхнеуровневыми KPI. Часто этот ритуал повторяется каждую неделю.
- Маркетологи-исполнители контролируют расход бюджета, управляют кампаниями и креативами. В идеальных условиях — это происходит почти в режиме реального времени.
Рассчитывать ценность каналов по модели атрибуции будет полезно директору по маркетингу и менеджерам направлений. То есть второму и третьему уровням. Именно здесь регулярно и в полном объеме собираются необходимые оцифрованные данные, а довольно короткий период принятия решений позволяет реализовать весь цикл работ с построением и расчетом модели на основе машинного обучения.
Первый уровень, в свою очередь, обычно владеет большим количеством данных, особенно данных рынка, но в неоцифрованном виде. К тому же при принятии решений на этом уровне большее влияние имеет экспертное мнение.
А на четвертом уровне царствуют рекламные сервисы. Они располагают огромными объемами данных, и куда проще и разумнее не конкурировать с ними в использовании алгоритмов машинного обучения, а полагаться на их корректировки ставок и подбор ключевых слов. Так как для работы на этом уровне вам придется очень быстро выгружать терабайты данных, обрабатывать их и загружать обратно.
Минус моделей атрибуций, встроенных в рекламные сервисы, в том, что по отдельности они работают отлично, но невозможно сделать сравнительную оценку их между собой, так как все они имеют разные подходы в расчетах моделей.
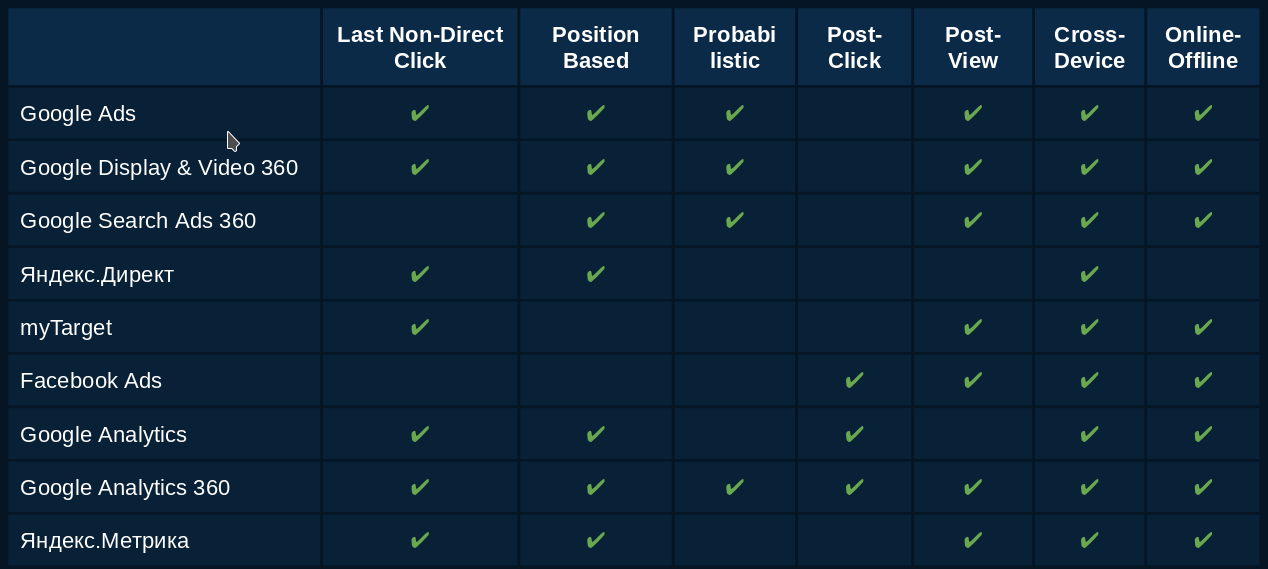
Условия для развития ML появились благодаря тому, что сервисы сбора и объединения данных увеличили общий объем доступных данных. Но важно, как были собраны эти данные. Например, данные с сайта, собранные javascript-трекером, использовать для машинного обучения нельзя. Поэтому все ваши методы сбора данных должны будут пройти адаптацию к требованиям данных для ML.
Давайте рассмотрим, какие еще условия нужно соблюсти компании, чтобы разработанная ML-модель атрибуции была действительно успешной.
Основные требования к модели
Обычно все начинается с претензий к существующей модели: «У нас есть Last Click, и мы уверены, что она что-то не учитывает, а мы бы хотели достоверно распределенный доход по нашим рекламным кампаниям, имея в распоряжении, в первую очередь, данные о поведении посетителей нашего сайта».
В этот момент очень важно понять – нет какого-то эталона по распределению доходов от рекламных кампаний по модели атрибуции на базе машинного обучения. Вам не с чем сравнить вашу модель, чтобы убедиться правильно ли вам удалось рассчитать. И вероятнее всего, вы будете использовать несколько подходов к расчетам атрибуции на базе ML.
И если до начала разработки вы не знаете, какой именно из этих подходов вам нужно использовать и почему — вам стоит повременить с ML атрибуцией. Ответы на эти вопросы зависят от постановки задачи и того, насколько команда разработки понимает ожидания бизнеса от результатов внедрения модели атрибуции.
Может быть, в стратегическом и тактическом плане, им хотелось бы не только распределить доход, но и рекомендаций, как именно их перераспределить или, в идеале, узнать «что будет с конверсией, если мы вовсе отключим эту и эту компании». Многие вообще не в курсе, как применять знания, которые предоставила модель. Словом, для такого расширенного набора ожиданий потребуется уже совсем другой набор формализованных знаний:
- Расходы на рекламу — какие суммы тратились на рекламу с разбивкой по сессиям;
- Природа каналов — какие каналы органические, поддерживающие, закрывающие;
- Емкость каналов — как долго и много можно вкладывать деньги в каждый канал, чтобы они все еще приносили прибыль;
- Тренды рынка — например, если часть мобильного трафика растет, то вам следует за ним поспевать;
- Активности конкурентов — цена у конкурентов также влияет на конверсию на ваших страницах, как и то, что они ведут свои рекламные кампании и выкупают позиции в выдаче;
- Данные о показах на уровне пользователя — как бы не хотелось располагать этими данными, но большинство сервисов анонимизируют эти данные или не предоставляют их вообще.
Многие из указанных категорий данных — недоступны или их невозможно формализировать. Поэтому функция модели атрибуции смещается — от нее ожидают больше советов и подсказок, чем инструкций. И в условиях ограничений по данным — это самый вероятный сценарий использования — не data-driven, а data-informed, где данные используются наряду с экспертными знаниями. В реализации этого подхода важно, чтобы модель давала объяснимые результаты — чтобы было понятно, что и откуда пришло, а также указывала на уровень достоверности своих расчетов, учитывая надежность и наличие данных. Ведь на этих результатах будут приниматься важные тактические и стратегические решения.
Применение экспертных знаний в машинном обучении
В нашем контексте экспертные знания — это данные о специфике бизнеса, ниши, поведения пользователей, которые влияют на то, как данные для расчетов собираются, хранятся и объединяются.
Для построения модели атрибуции на машинном обучении, обязательны знания в следующих областях:
Конверсионное окно — сколько времени требуется большинству пользователей от первого взаимодействия до заказа?
В зависимости от того 20, 40, или 90 дней составляют ваше конверсионное окно, разные категории товаров или сегменты пользователей могут иметь очень различные значения по конверсиям. Если конверсионное окно больше месяца, то играет роль время проверки данных о конверсиях, когда нужно автоматически включить все конверсии предыдущего месяца на начале следующего, а не только конверсии текущего.
Все эти нюансы, конечно, хочется настраивать без разработчиков. И это также важно.
Выбор управляемых каналов — оценка первостепенных каналов, которыми реально управлять и которые обычно требуют перераспределения бюджета для повышения эффективности.
Часто в расчет модели атрибуции включают данные о каналах, которые не имеют прямых расходов. Так часто бывает, к примеру, с email-каналом — его оценка не даст подсказок, что с ним дальше делать. Или же успешность брендовых кампаний — значит ли это, что нужно еще больше в них вкладываться? Обычно нет, ведь их емкость может быть уже исчерпана.
Но даже после получения первых советов с учетом конверсионного окна и после выбора нужных каналов, вам стоит осторожно относится к полученным результатам. И все потому что у рекламных каналов существует своя специфика.
Синергия рекламных каналов — почему нужно сохранять спокойствие, получая советы отключать отдельные рекламные кампании?
Структура продаж и то, как рекламные кампании влияют на эти продажи, трудно представить линейно — канал влияет на канал, пользователь то из органического трафика придет, то из рассылки, где-то сработала работа с инфлюенсерами, а еще и акции со скидками. И поскольку рекламный бюджет общий, каналы неизбежно влияют друг на друга. Но они также предопределяют друг друга, например, дисплейная реклама увеличит конверсии поисковой, вырастет директ канал и в результате — улучшатся конверсии по воронке.

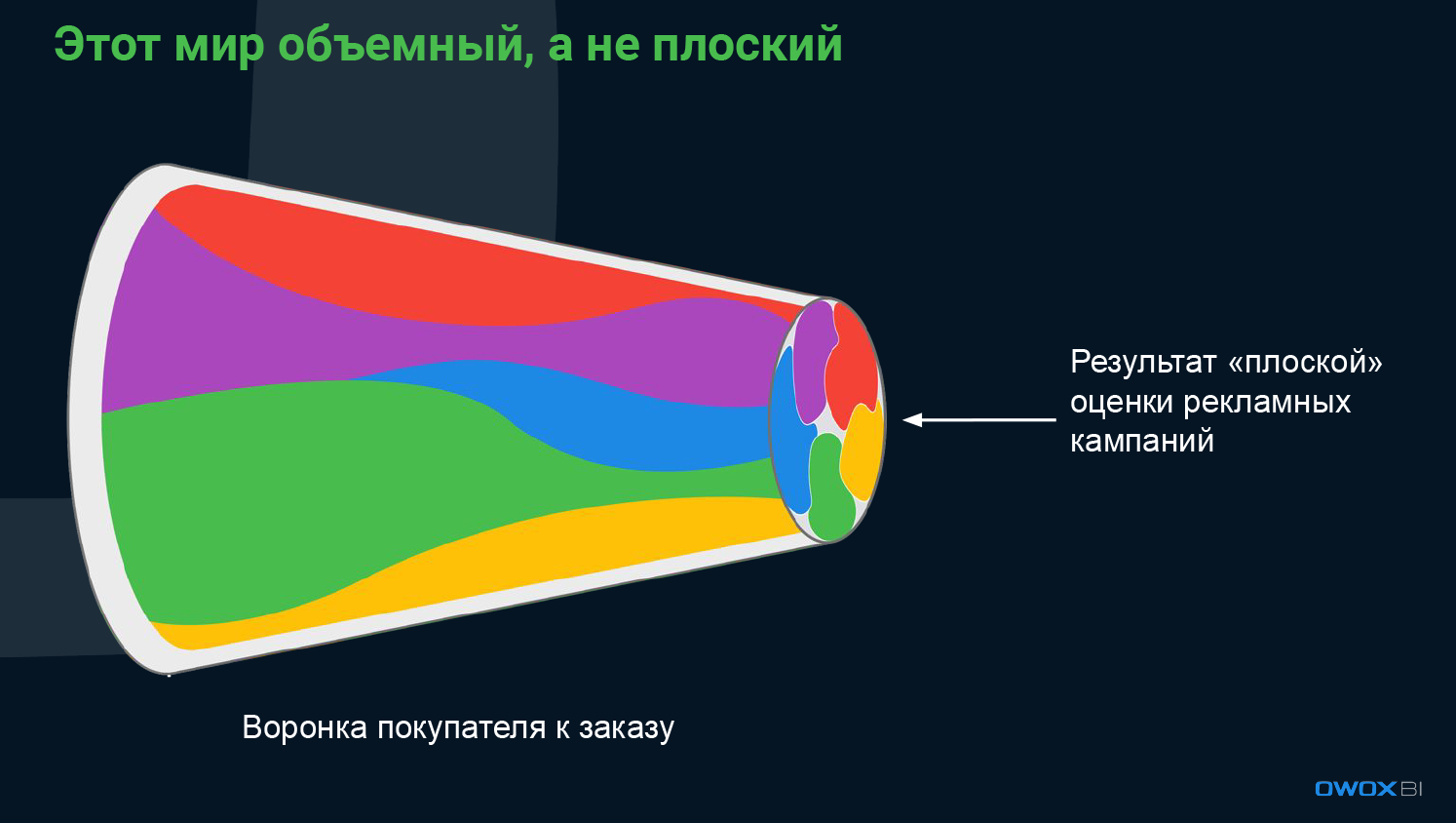
Если полностью исключить любую из составляющих этого общего концерта — очевидно, какое-то влияние пропадет, где-то настроенные цепочки не сработают, и общий объем продаж может упасть.
Так что именно здесь можно узнать с помощью атрибуции? Какой вклад этого канала в общие продажи? Да, но не только, ведь можно еще узнать:
- Какой прирост дал продажам этот канал? Этот вопрос включает в себя и ассоциированные конверсии.
- Насколько уменьшатся продажи, если отключить канал? Этот ценный ответ можно получить еще до отключения канала.
- И приятный бонус: сколько продаж приносит сам канал по оценке самого канала? С какой вероятностью пользователь конвертируется?
Вот с этими ответами, поддерживающими основной вопрос, можно получить глубокое видение ситуации и оценить канал не только в рамках последних успехов (или провалов), но и общего его влияния на всю структуру продаж.
Учитывать то, как оценка рекламных кампаний влияет на воронку, и понимать, как эта оценка сформулирована
Мы заметили, что недостаточно просто оценивать прибыльность каналов и получать подсказки по перераспределению бюджета. Важно понимать, какой вклад несет каждый из каналов и как этот вклад меняется в зависимости от шага воронки. Например, если посмотреть в таблицу ниже, то кажется, что стоит довериться рекомендации и сократить бюджет на 19% (колонка Budget Advice) для партнерского и display каналов. Но считать их абсолютно одинаковыми нельзя – ведь партнерский канал лучше всего конвертирует на последних шагах воронки (62% в Action колонке).
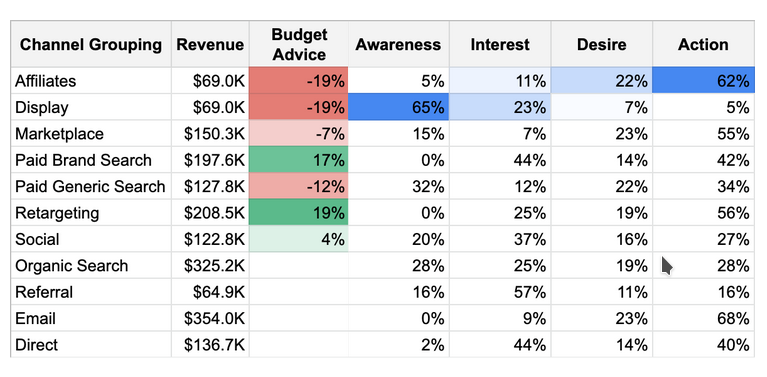
Представьте себе, сколько можно потерять прибыли, слепо доверившись рекомендации алгоритма и урезав такой канал. Также не рекомендуется урезать тот канал (в этом случае — display), который ведет большую часть трафика. Плохие показатели на следующих этапах воронки могут указывать на то, что этому каналу нужна поддержка, чтобы работать лучше.
А этот инсайт уже более полезен, чем совет «рубить сук, на котором сидишь».
Вместо послесловия: спешить некуда
Будущее — за моделями, обученными на рыночных данных. Готовьтесь к построению моделей атрибуции на основе машинного обучения основательно. Вникайте в процессы, в значение данных, которые собираете и будете использовать. Выработайте кристальное понимание расчета, ведь атрибуций с «черным ящиком» вместо понятного алгоритма расчета и так хватает. Если появился острый соблазн урезать весь бюджет на какой-либо источник по совету построенной модели, помните об опасности потерять намного больше из-за сужения общего объема продаж. А восстанавливать прежний, наработанный уровень может быть дороже, чем та экономия, которую вы получите, урезав канал.
Использование ML-технологий — это вопрос зрелости, умения углубляться в нюансы и не полагаться на искусственный интеллект, даже когда очень хочется. Особенно что касается уровня исполнителей — это совсем не сфера быстрого применения ML.
Все интересное про диджитал у нас в телеграме, а может быть и у вас: https://t.me/performance_360